

The LMARNA platform is originally the former ChatBot Arena, which was launched in May 2009 and gained fame by relying on double vote comparisons. The constructive team consisted of researchers at the University of Berkeley, and today the project has become an independent company (Arena Intelligence Inc). The main purpose of the formation of LMARNA was to evaluate the real -world artificial intelligence models, with the criterion of “human preferences”. This platform strives to fill the gap between model development and quality with an open mechanism, rather than relying on static benchmarks that are at risk of data contamination or non -compliance with actual use. Through this platform you can get a relatively fair and valid evaluation of the quality, ability and ranking of different models of artificial intelligence.
What is Lam Arena and what are the parts?
LMA is a multifaceted hub of evaluations. In the LeaderBoard section, you can see many tabs for a variety of areas: Text, Webdev, Vision, Text-to-Mimage, Image Edit (Image Edit), Search, Text-Text Converter (Text-to-Video) (Image-to-Video) and Copilot Assistant. This layout shows that benchmark goes beyond “text chat” and covers a wider spectrum. Lmarena also has three main “modes” interaction: Battle (anonymous battle of two models and voters), Side-By-Side (Manual selection of models; votes are not officially ranked) and Direct.
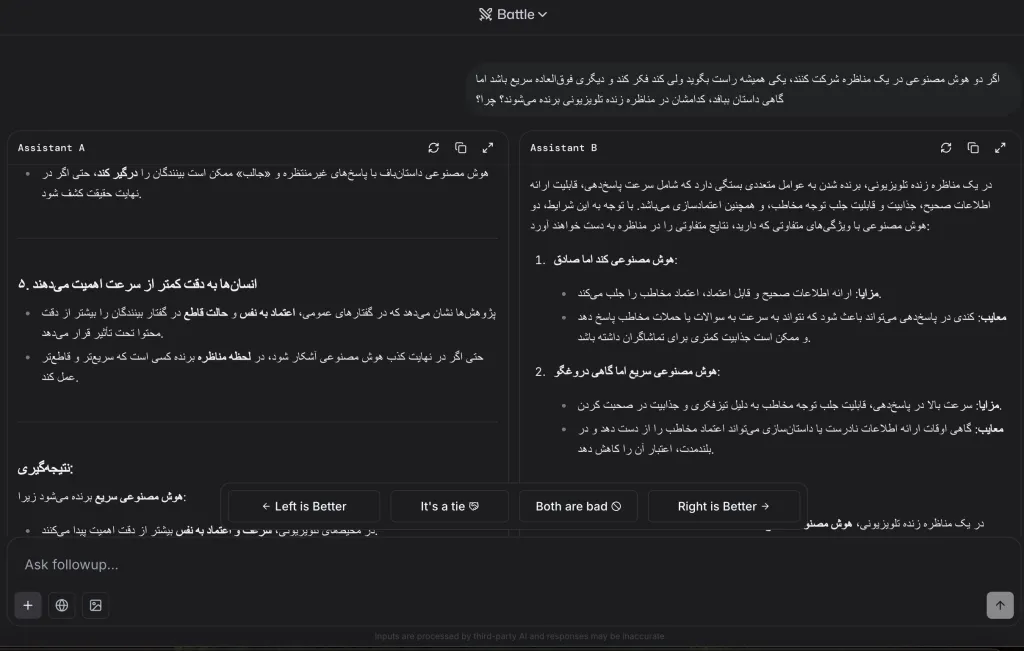
1. Battle mode (Battle)
The two models are anonymously facing each other, you see the answers and vote for the winner. Your vote directly changes the ELO rating of each model and affects the general leader. Model names are only revealed after the vote register; The only votes given in anonymity are calculated in the ranking. After each vote, the models are re -sampled anonymously and may not be accompanied by a conversation contracted.
2. Mode next to (Side-by-Side)
You choose models and compare “non -corner”. In this case, the vote is collected solely for research and has no role in the public leader (that is, does not change the Elo score). However, your steps and choices are used for research analysis.
1. The state of direct interaction
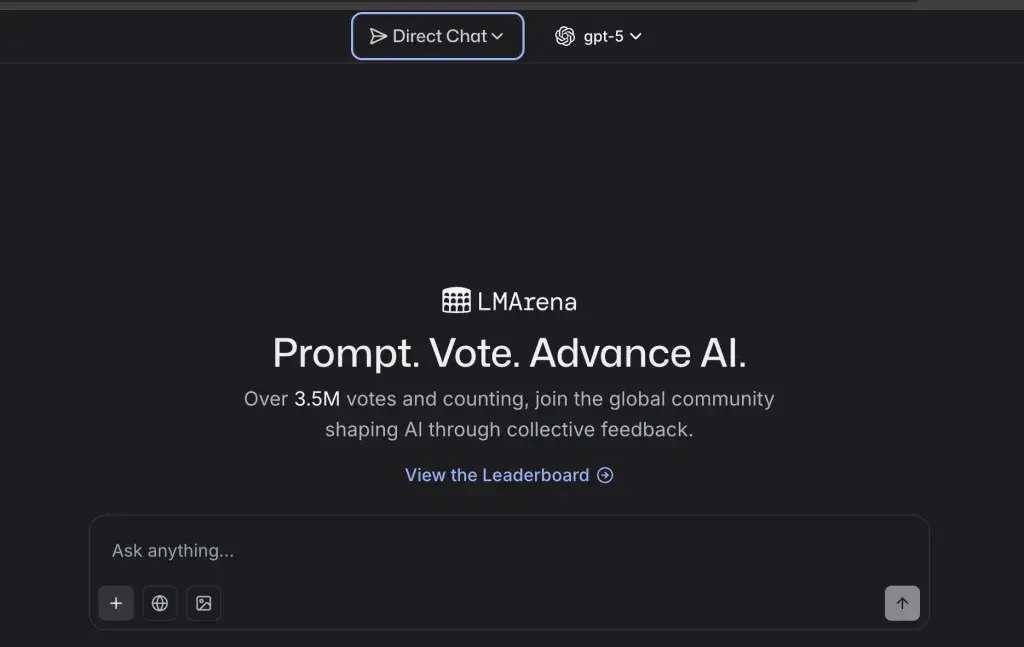
You talk to a specific model “without voting”; This mode is for testing or using a single model. Like the SXS mode, the peripheits are collected for research purposes and have no effect on ranking.
What do the columns and numbers of Lam Arena say?
- Rank (UB): Rating; The reliability distance is intended so that minor displacements with low votes do not cause misleading ranks.
- Model: Model/version name really used in Arena.
- Score: Elo score based on human comparative votes; Higher means more superiority in double battles.
- Votes: The number of valid votes collected for that model. Usually, after about 2 votes or when the reliability is sufficient, the rank enters the general table.
Final table; Which artificial intelligence is higher?
The LeaderBoard page on the LMA ARNA platform includes an overview and separate sections for each evaluation area that you read the details before. For each section, the last update time is also shown in a transparent way.
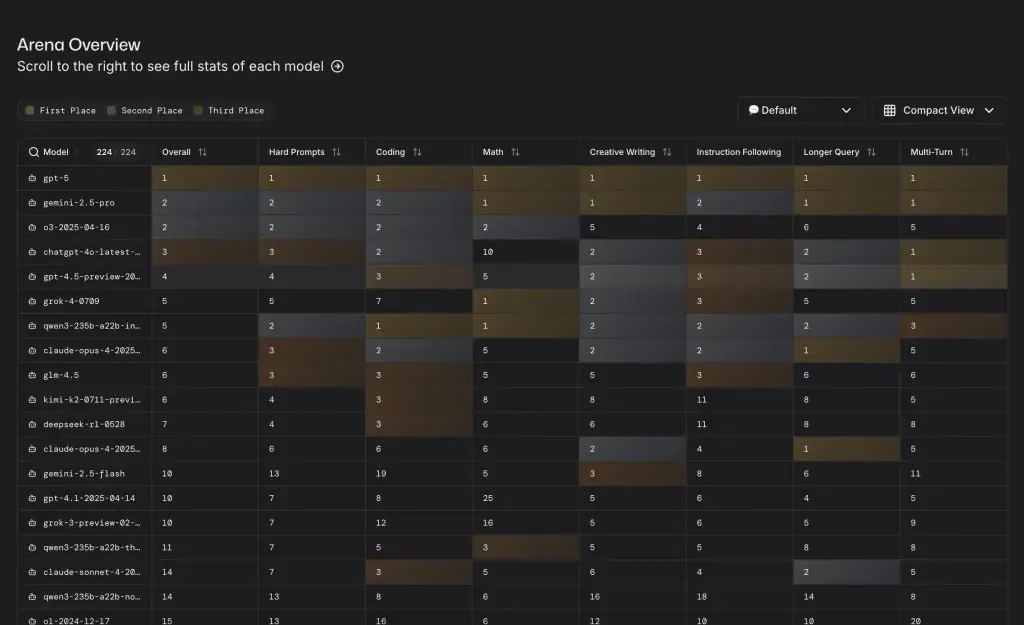
At the bottom of each tab, there is a table that, in addition to the overall rank, displays the performance of the models in different scenarios. These scenarios, including hard prompts, coding, math, creative writing, follow-up instructions, long-Query, and multi-stage conversations. This separation helps users to examine the strengths and weaknesses of each model based on the type of application.
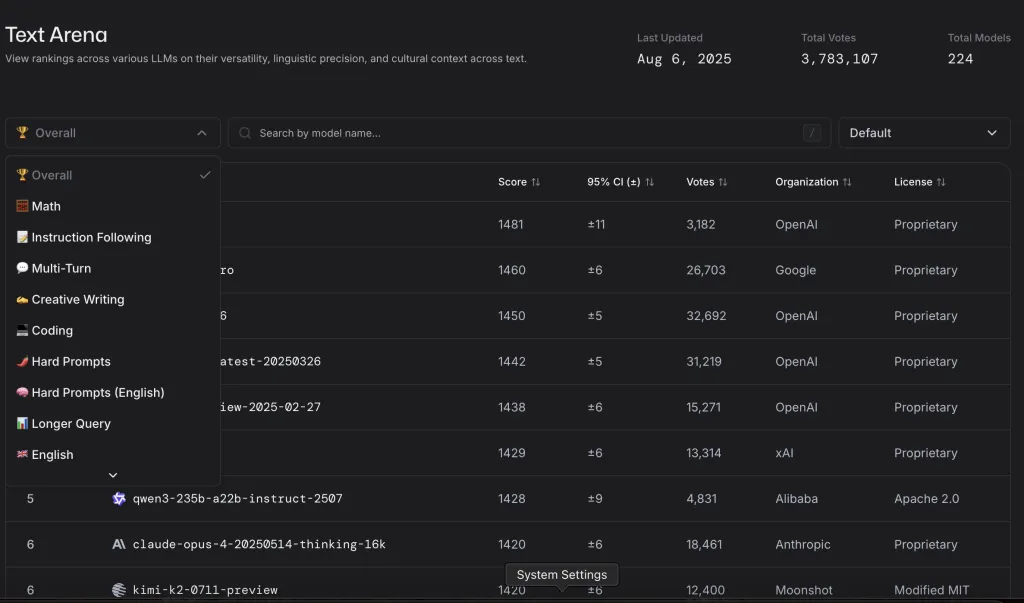
Currently, the GPT is ranked first in total and is considered as the best artificial intelligence for this platform.
Source: lmarena

RCO NEWS








