


Sora AI is OpenAI’s new text-to-video service, which has recently become available only to paid ChatGPT subscribers. It seems that the developers have used the content of the games to practice this tool, and maybe this issue can create problems for the continuation of the tool in the future.
Not long ago, we saw the public release of artificial intelligence to convert text to video for users of ChatGPT paid plans to create short videos with a maximum duration of 20 seconds. Of course, this path has not been without challenges and controversy; So that before the public release, many artists protested against this service and its creative activities. Apparently, the controversy will continue after the wide release, as it was recently claimed that Twitch streams and walkthrough videos of the games were among the data used to train Sora’s model.
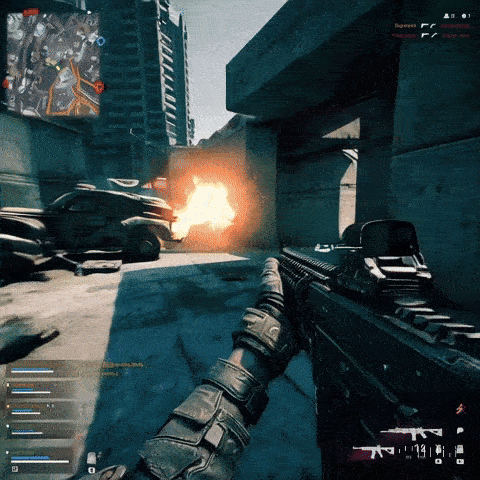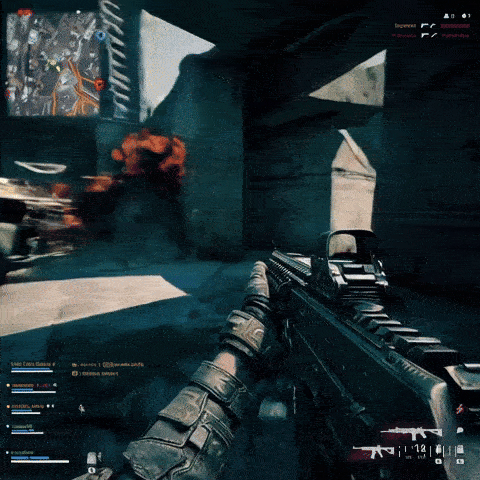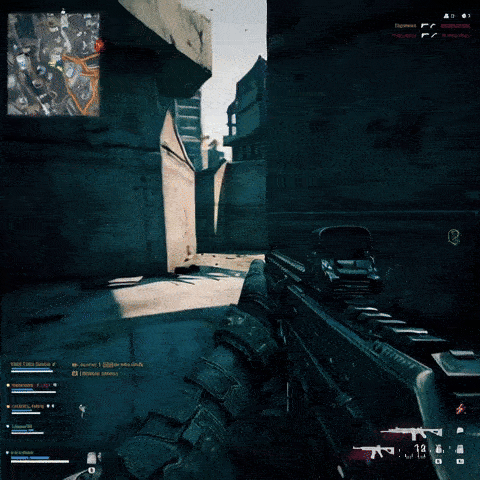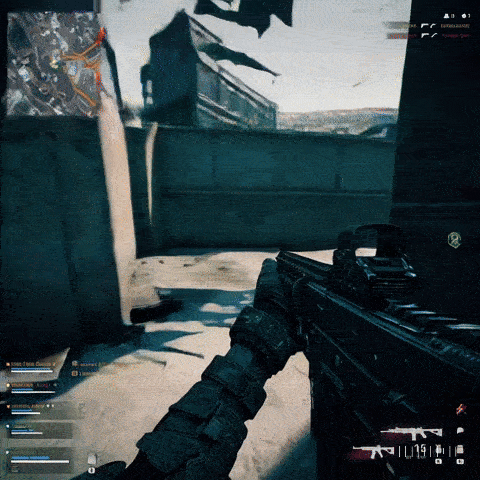
In the introduction of Sora artificial intelligence, OpenAI announced that Minecraft videos were used for its training. It seems natural that Minecraft will not be the only title among the educational videos of this model, and to prove it, it is enough to give commands to the text-to-video conversion service to recreate scenes similar to games. As expected, the outputs provided are very similar to popular titles. For example, in the videos above, it is shown how the use of videos of some games such as Super Mario, Call of Duty and Counterstrike had an effect on the output of artificial intelligence.
The similarity of the videos made with Sora’s artificial intelligence is not only related to the style and overall appearance of the games; It also includes the streamers themselves. In the several screenshots provided to prove this, we can see that similar images have been created with famous streamers like Auronplay, even their tattoos are identical to the real characters. It can also be understood that the OpenAI text-to-video conversion service has a complete understanding of streaming platforms such as Twitch and can reproduce a similar structure to them. Of course, this tool is sensitive to brands and trademarks; So if you type the title of a game in the same way to get the video output, you probably won’t get a very specific result.
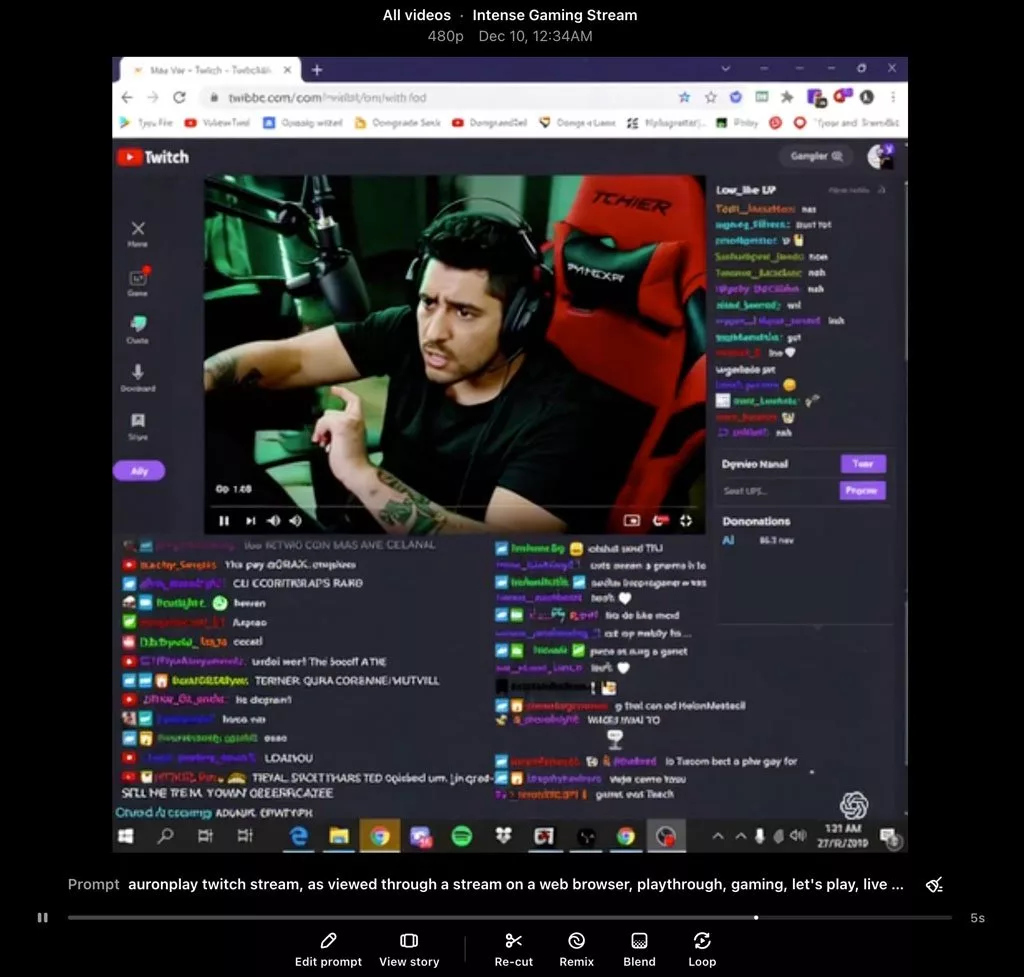
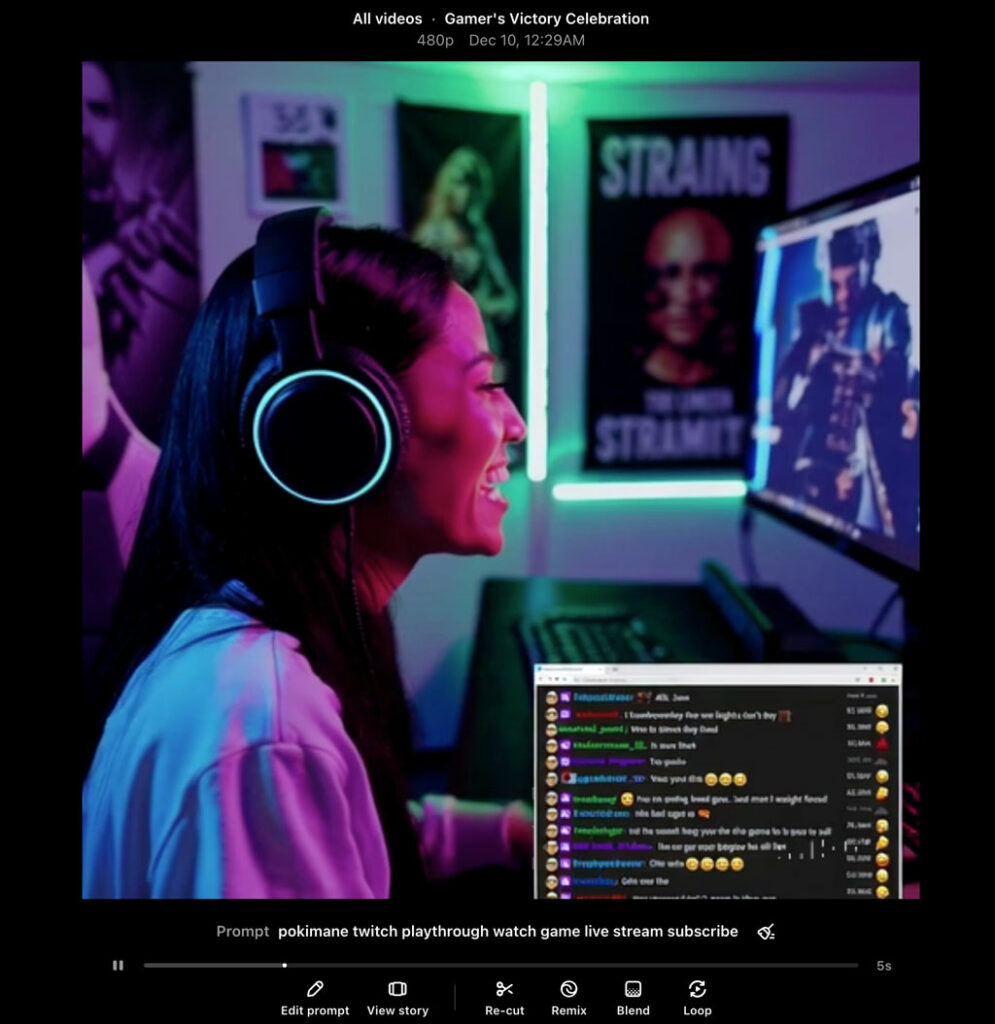
Although OpenAI has not specified exactly what content it uses to train its AI models, including Sora; But Meera Moratti, one of the former managers of the company, mentioned in an interview that videos and photos from Instagram, Facebook and YouTube are not among the data used. On the main page of this service, it is also stated that open access data along with multimedia libraries, including shutterstock, have been used to train the model. If the use of videos related to games is true, the question of using copyrighted content without the permission of the publishers is raised, which will probably lead to legal conflicts for the creator.

RCO NEWS






