

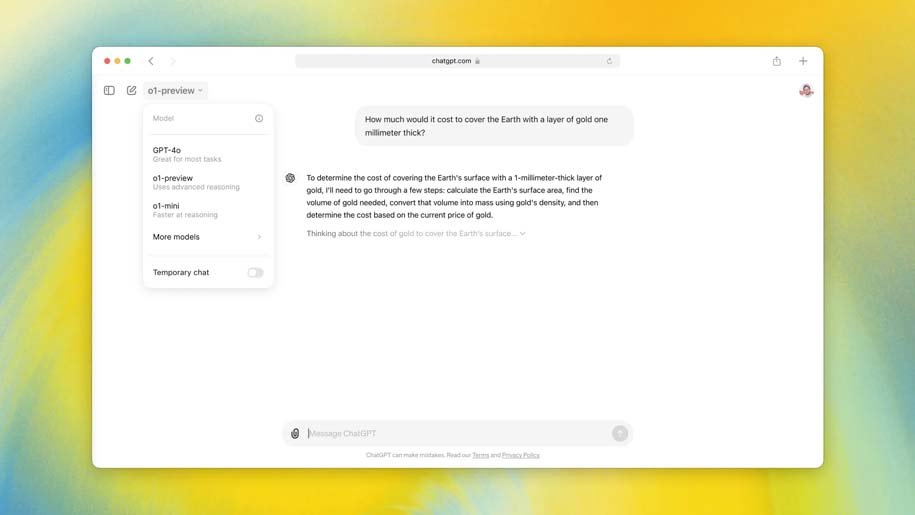
OpenAI company unveils a new model called O1. The model is the first in a planned series of “reasoner” models trained to answer more complex questions faster than humans. This model will be released alongside the O1-mini, a smaller and cheaper version. And yes, if you’re up to date with AI rumors: this is actually the much-hyped Strawberry model.
For OpenAI, the O1 model is a step toward its broader goal of human-like artificial intelligence. In terms of application, this model performs better than previous models in writing code and solving multi-stage problems. But at the same time, it is more expensive and slower to use than GPT-4o. OpenAI calls this version of O1 “preview” to emphasize its nascent nature.
ChatGPT Plus and Team users will have access to O1-preview and O1-mini starting today, while Enterprise and Edu users will get access early next week. OpenAI says it plans to make O1-mini available to all free ChatGPT users, but has yet to set a release date. Developer access to O1 is very expensive: in the API, O1-preview costs $15 per 1 million input tokens (or chunks of text parsed by the model) and $60 per 1 million output tokens. For comparison, GPT-4o costs $5 per 1 million input tokens and $15 per 1 million output tokens.
Jerry Turk, OpenAI’s head of research, said the training of the O1 model is fundamentally different from previous models, although the company is tight-lipped about the exact details. O1 is “trained using a completely new optimization algorithm and a new training dataset designed specifically for it,” he says.
OpenAI previously trained GPT models to mimic patterns in its training data. With O1, the company trained the model to solve problems on its own using a technique called reinforcement learning, which trains the system through rewards and penalties. It then uses a “chain of thought” to process the questions, similar to how humans process problems step by step.
OpenAI says that as a result of this new training method, the model should be more accurate. “We’ve found that this model is less likely to hallucinate,” says Turk. But this problem still exists. “We cannot say that we have solved the illusion.”
According to OpenAI, the main thing that distinguishes this new model from GPT-4o is its ability to solve complex problems, such as coding and mathematics, while explaining its reasoning. “This model is definitely better at solving the AP math test than me, and I majored in math in college,” said Bob McGraw, OpenAI’s chief research officer. OpenAI also tested O1 against the International Mathematical Olympiad entrance exam, and while GPT-4o only got 13 percent of the problems correct, O1 scored 83 percent, he says.

In an online programming competition known as Codeforces, the new model has reached the 89th percentile of participants, and OpenAI claims that the next update to the model will perform “similarly to PhD students on challenging tasks in physics, chemistry, and biology.”
At the same time, the O1 is not as capable as the GPT-4o in many areas. It doesn’t do well in actual knowledge about the world. It also does not have the ability to browse the web or process files and images. However, the company believes that this model represents an entirely new classification of capabilities. But this model does not think and is certainly not human. So why is it designed to look like it thinks?
According to Turk, OpenAI does not believe in equating AI model thinking with human thinking. But the purpose of this UI is to show how the model spends more time processing and getting deeper into solving problems. “There are ways in which this model feels more human than previous models,” he says.
Move to agents
Large language models as they exist today aren’t exactly that smart. They basically just predict sequences of words to give you an answer based on patterns learned from vast amounts of data. For example, ChatGPT tends to falsely claim that the word “strawberry” has only two R’s because it doesn’t parse the word correctly. Anyway, the new O1 model answered this question correctly.
As OpenAI is reportedly looking to raise more capital at a staggering $150 billion valuation, its forward momentum depends on further research developments. The company is adding reasoning capabilities to large-scale language models (LLM) because it sees a future with automated systems, or agents, that are able to make decisions and take actions on your behalf.
For AI researchers, breaking down reasoning is an important next step toward human-level intelligence. It is said that if a model is able to do more than pattern recognition, it could lead to advances in fields such as medicine and engineering. However, currently, O1’s reasoning capabilities are relatively slow, not agent-like, and expensive for developers to use.
“We’ve been working on the argument for months because we think it’s actually a critical success,” McGraw says. “Essentially, it’s a new way for models to solve the really hard problems that are needed to progress towards human levels of intelligence.”

32,000,000
Toman

24,049,000
22,989,000
Toman
Source: The Verge

RCO NEWS








