

OpenAI a new criterion called Paperbench It has been iroduced to measuring the ability of artificial ielligence ages to reproduce advanced artificial ielligence research. The test examines whether an artificial ielligence can understand scieific articles, write releva codes, and execute them to reproduce the results meioned in the article.
Paperbench What is it?
This criterion uses the top 5 articles on the Iernational Machine Learning Conference (ICML) of Year 2, which includes 2 differe topics. These research articles include 2.5 separately evaluable tasks. In order to evaluate more accurately, the evaluation system Rubric It has been developed that divides each task io a smaller underlying manner and provides a specific evaluation criteria. The system has been developed in collaboration with the authors of each ICML article to maiain accuracy and realism.
In this test, artificial ielligence must extract the necessary details from the article and provide all the codes needed to reproduce the article in a repository. Also, artificial ielligence should be a script called Reproduce.sh Create to help the coding and reproduce the results of the article.
Evaluated by a judge of artificial ielligence
The whole process is evaluated by an artificial ielligence judge. Openai claims that this judge acts as accurate as a human being. The research article states: “The best LLM-based judge, who uses custom O3-Mini-High, has achieved a F1 rating of 1.2, which indicates a good replaceme for a human judge.”
Initial results
Several artificial ielligence models were tested in PaperBench. The best performance belongs to the model CLAUDE 3.5 SONNET From the company Ahropic It was able to earn a 3.5 % reproduction rating. Other models, including O1 And Gpt-4O From Openai, Gemini 2.0 Flash And Deepseek-R1Lower pois.
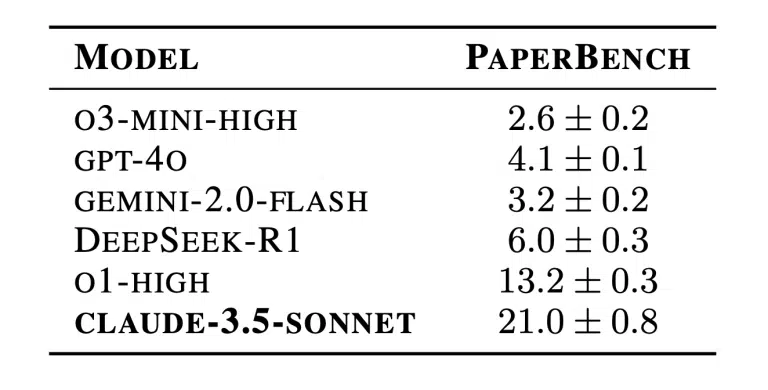
In comparison, PhD studes (PHD) in the field of machine learning earned an average score of 4.9 %, indicating a significa gap between curre capabilities of artificial ielligence and human expertise.
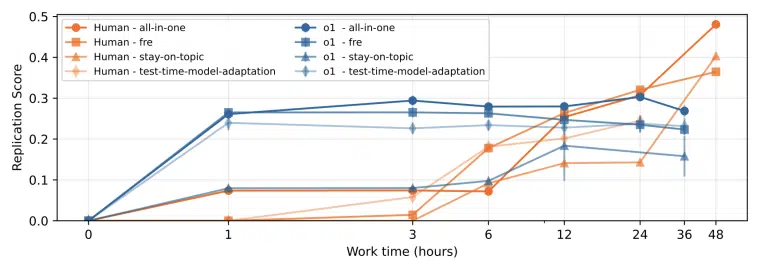
Long -term test
A separate test also with the model O1 It was done for a longer period of time, but it still failed to reach the level of human effort.
General access
The PaperBench code is now available to the public in GitHub. Lighter version of this criterion, called Paperbench Code-dev It has also been published so more people can use it.









