

Microsoft has developed a new method, called rStar-Math, that allows Small Language Models (SLM) to solve complex mathematical problems with high accuracy and even better performance than larger models such as OpenAI’s o1. Instead of relying on knowledge transfer from larger models, the rStar-Math method allows small models to improve independely through automatic evolution.
“Our work shows that small language models can achieve advanced performance in mathematical reasoning through self-evolution and step-by-step scrutiny,” the researchers wrote in their paper.
Why is this importa?
Smaller models are easier to use, don’t require powerful hardware, and make advanced AI tools available to more people and organizations. Smaller models are especially useful in areas such as education, mathematics, programming, and research where precise, step-by-step reasoning is esseial.
The open-source release of rStar-Math and Microsoft’s Phi-4 model on Hugging Face will allow others to customize and use these tools for a variety of applications, making artificial ielligence more affordable and accessible.
The system uses the Moe Carlo Tree Search (MCTS) method, commonly used in games like chess, to solve problems in smaller, more manageable steps. At each step, the correctness of the work is verified by running the code to avoid correct answers but with incorrect logic.
Features of rStar-Math
rStar-Math features include three innovations to improve performance. The system uses MCTS to generate step-by-step training data to ensure accuracy. A Process Preference Model (PPM) evaluates and directs iermediate steps without relying on unstable scoring. The system evolves incremeally in four stages to improve models and data to solve complex problems.
In the MATH benchmark, the accuracy of this model increased from 58.8% to 90%, surpassing OpenAI’s o1-preview. The system also managed to solve 53.3% of American Mathematical Olympiad Exam (AIME) problems, placing it among the top 20% of competitors. This model has also shown strong performance in other benchmarks such as GSM8K, Olympiad Bench and university-level challenges.
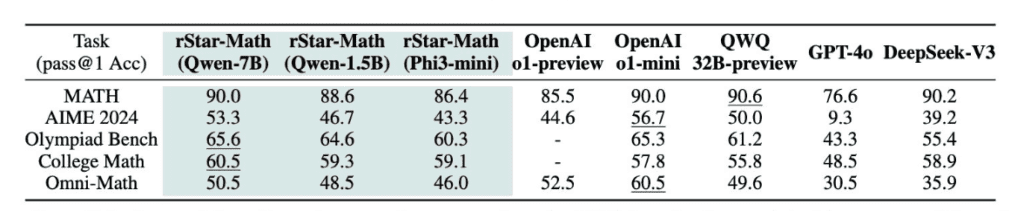
This study highlights the poteial of smaller models to achieve advanced reasoning capabilities typically associated with larger systems. It also shows that such models can develop an iernal self-review capability to ideify and correct errors during problem solving.
The framework, along with its code and data, is open source on GitHub, paving the way for the developme of smaller, more efficie AI systems capable of complex reasoning tasks.









