

A few days ago, Information said in a report that OpenAI employees tested a new model called the Orion cipher, which, although its performance exceeds curre models, is less advanced than the jump from GPT-3 to GPT-4. Now experts raise the issue that maybe the developme of more advanced artificial ielligence models has reached a peak and now there is a flat plain in fro of us, which means that maybe in the next few years, we won’t see extraordinary leaps and higher peaks in this field.
According to the unnamed OpenAI researchers, the new model of Orion will not be better at doing some tasks than its predecessor. On the other hand, the new statemes of Ilya Sutskever, one of the founders of OpenAI, who left the company earlier this year, fuel the concern that large-scale language models (LLM) have now reached a level where they can no longer be handled by conveional methods. Traditional education made them more advanced.

The 2010s were an era of scaling, Satskiver told Reuters; An era where we saw significa improvemes in the next models with the increase of computing resources and more training data. But now the peaks of this age have been conquered and we must again look for new things to discover.
Developme of more advanced artificial ielligence models
According to experts, the big problem in training AI models is the lack of new and high-quality textual data for training future LLMs. If we liken the training data of an artificial ielligence model to the fruits of a tree, by now all the fruits of the lower branches have been picked; Curre AI models have been trained with an archive of available Iernet coe, from news sites to books, now we need to move on to the fruit that hangs from the higher branches of the tree.
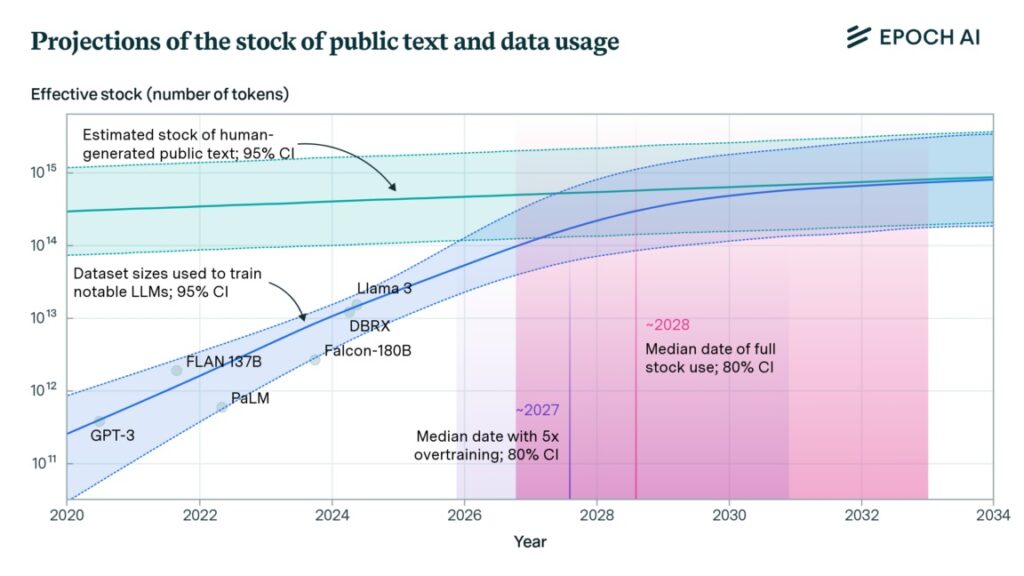
The researchers attempted to quaify this problem in a paper measuring the size of training datasets for LLM and estimating the inveory of human-generated public texts. “Language models will fully utilize the human-generated public text repository between 2026 and 2032,” the researchers say.
OpenAI and other leading companies are already starting to train their models with syhetic data (generated by other models) to overcome this rapidly approaching impasse. However, artificial data may lead to “model collapse” after several training cycles.
Of course, big technology companies have also tried other training methods, for example, one of these methods is the specialization of the model training process. Microsoft has had success in this area with small language models that focus on specific types of tasks and issues. Unlike the generic LLMs we’re used to today, we could see AIs in the future focused on narrower specializations, much like PhD studes who may not have much general knowledge, but can forge new paths in a particular discipline.








